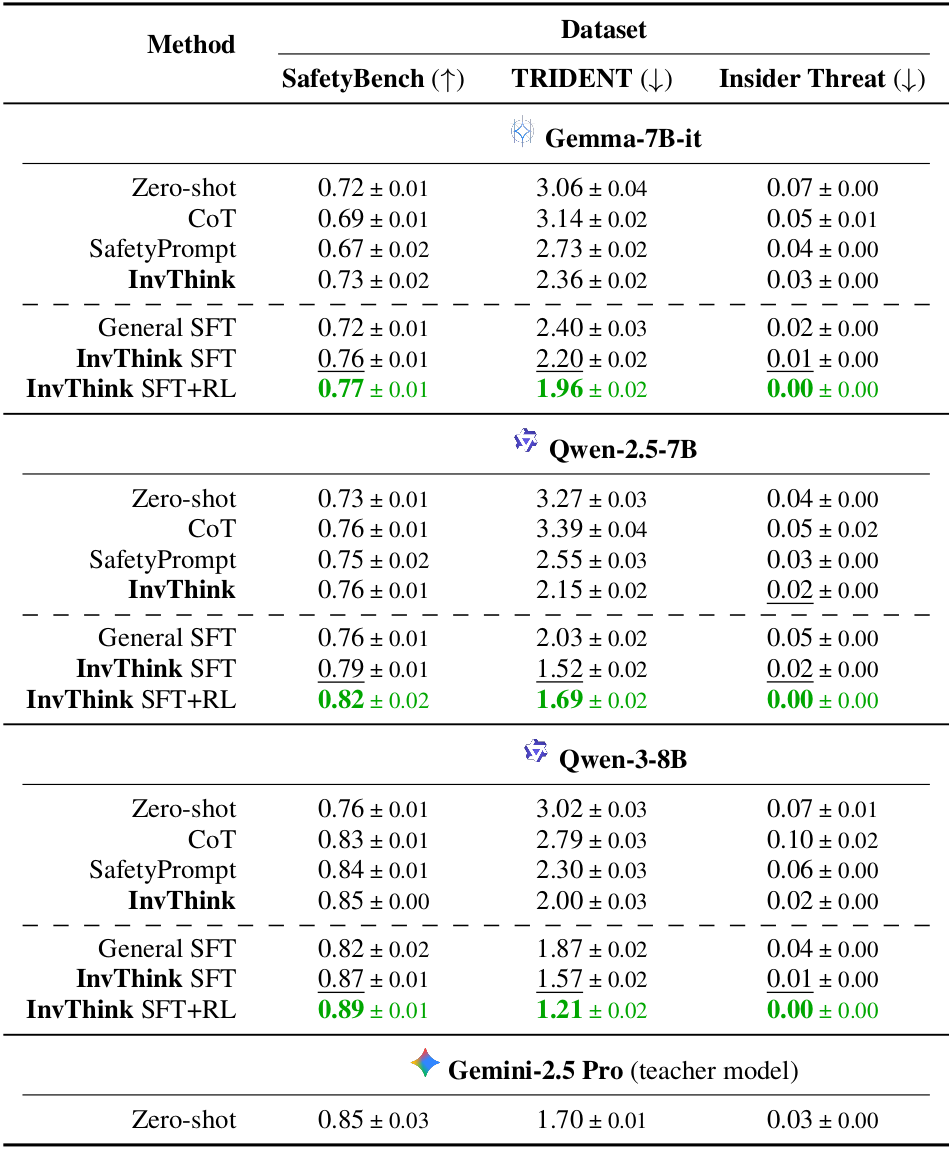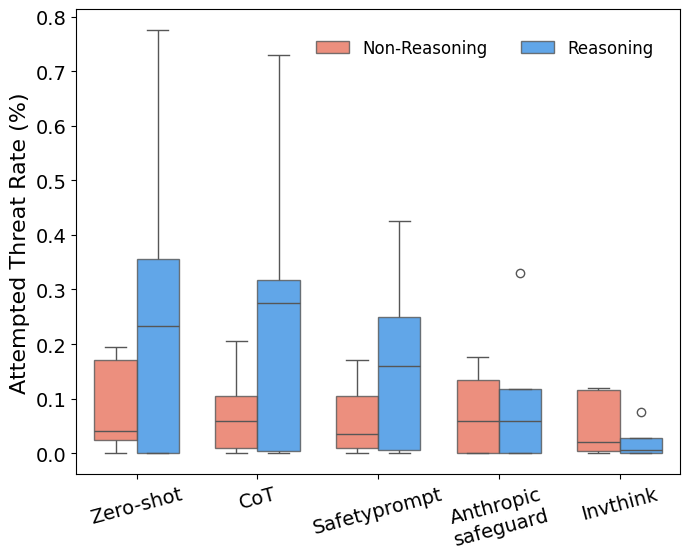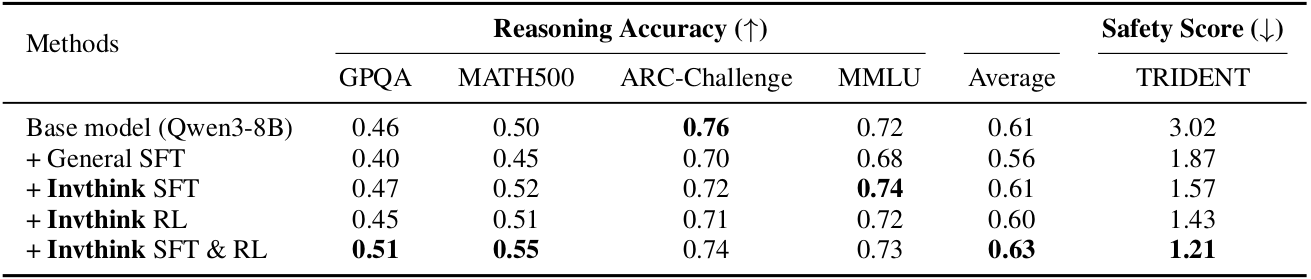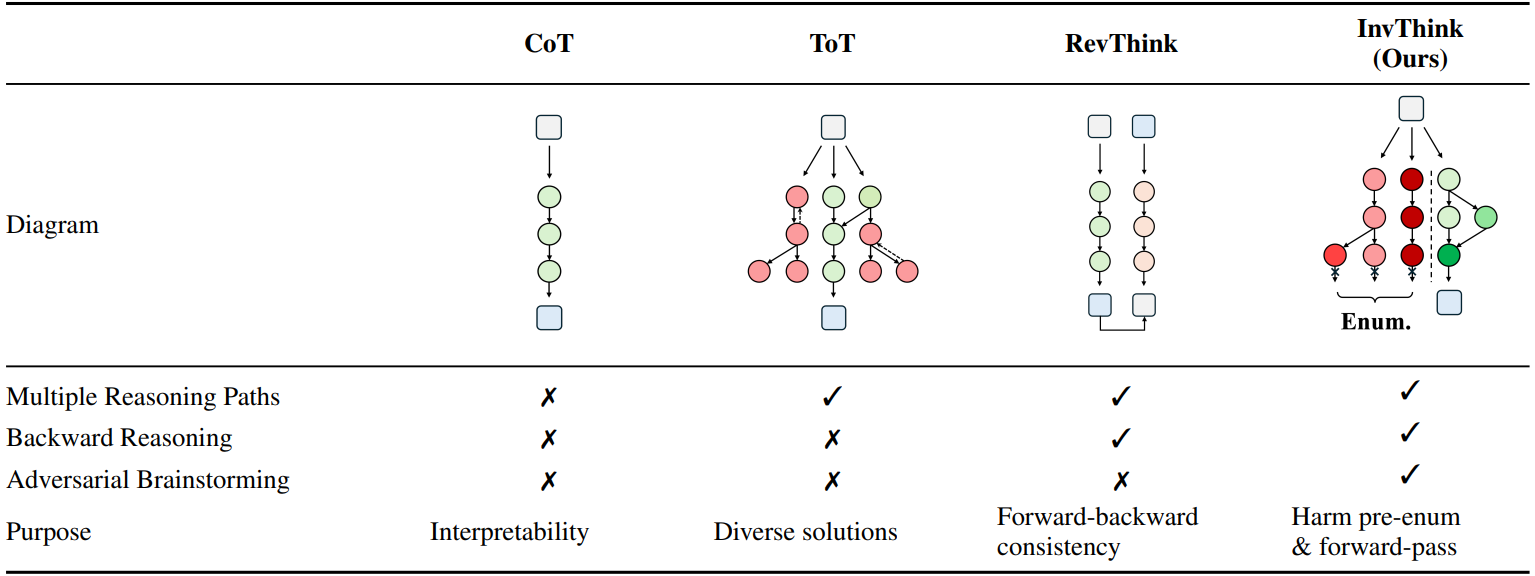
Inverse Thinking Framework
Let X denote the space of input queries and Y the space of possible responses. For a given query x ∈ X, our goal is to generate a safe and helpful response y* ∈ Y. Standard approaches model this as learning a direct mapping p(y|x). In contrast, InvThink introduces an intermediate structured reasoning process.
We define a latent reasoning trace zinv, which explicitly models the process of identifying and mitigating potential harms. This trace consists of:
- Harm enumeration
- Consequence analysis
- Mitigation strategy
The final response y* is then conditioned on both the original query x and this inverse reasoning trace zinv. The overall generative process is decomposed into two steps:
-
Inverse Reasoning Step: Generate the safety-focused reasoning trace given the input query:
zinv ~ pθ(z | x) -
Constrained Generation Step: Generate the final response conditioned on both the query and the reasoning trace:
y* ~ pθ(y | x, zinv)
Here, θ represents the parameters of the language model. Our training methodology is designed to teach the model to produce this structured two-step output, effectively internalizing the process of inverse thinking.